Why I Open-Sourced Beekeeper Behind a Wall — and What's Inside It
A small story
A friend was demoing an agent framework to me last month. Cute setup — a chat interface, a couple of tools wired up, a slick UI. He typed: “clean up the duplicate rows in the customers table.”
The agent thought for two seconds, generated SQL, and ran it.
Against production. Against a database that had no foreign-key constraints set up the way the agent assumed. The “duplicates” weren’t duplicates. The cleanup nuked an afternoon’s worth of orders.
The agent had been trained, the model was correct, the tool was the right tool — but there was no buffer anywhere between “the model decided” and “the database wrote.” No guardrail, no HITL, no audit trail. Just intent → execution.
This is fine for demos. It is not fine for anything you’d put in front of real users or real data. And it is the default in almost every agent framework I’ve evaluated.
Beekeeper is my answer to that. Today I’m open-sourcing it.
github.com/Anmolnoor/beekeeper — Apache 2.0, Python 3.10+.
What Beekeeper is
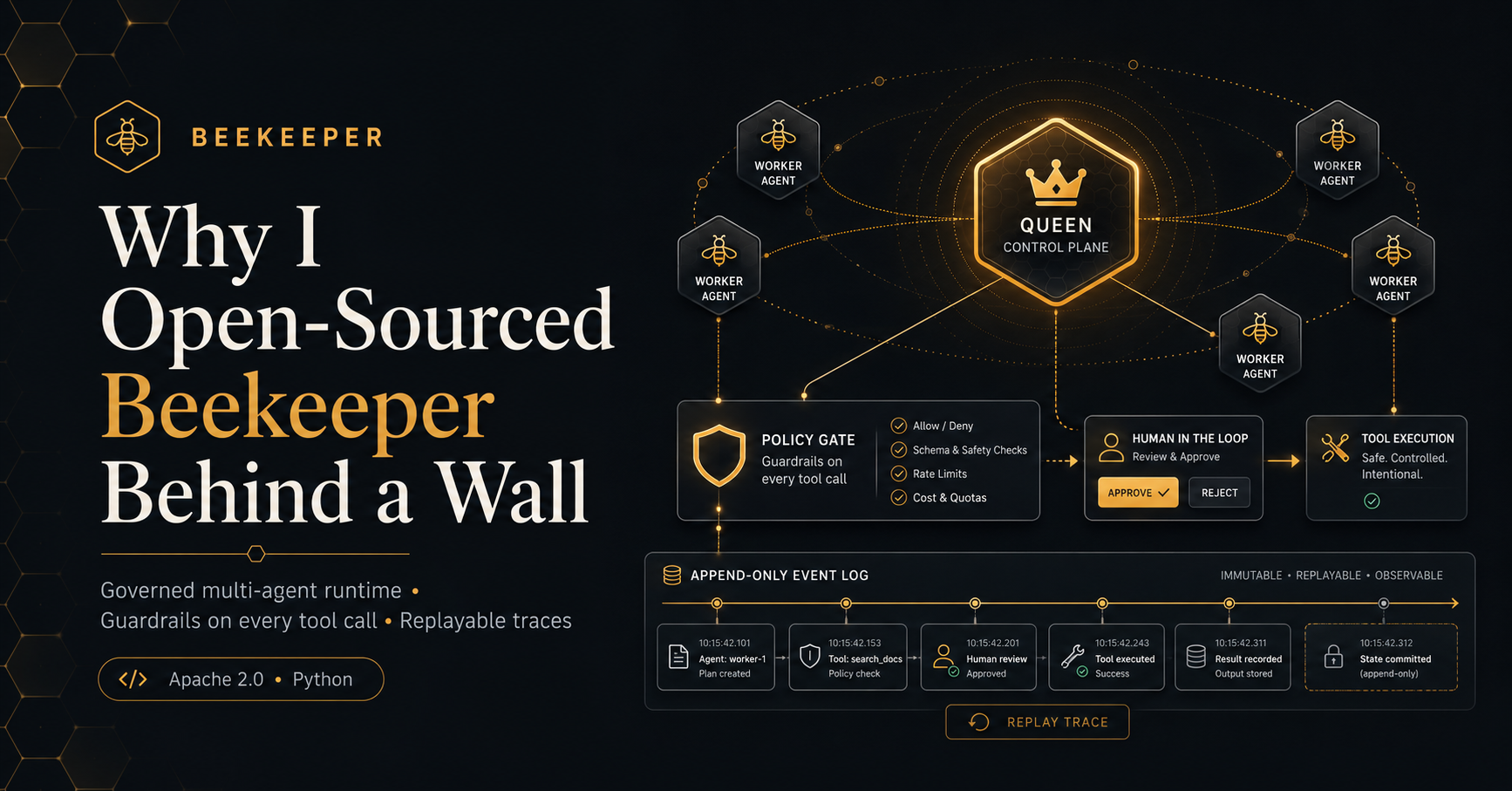
A multi-agent runtime built around four things:
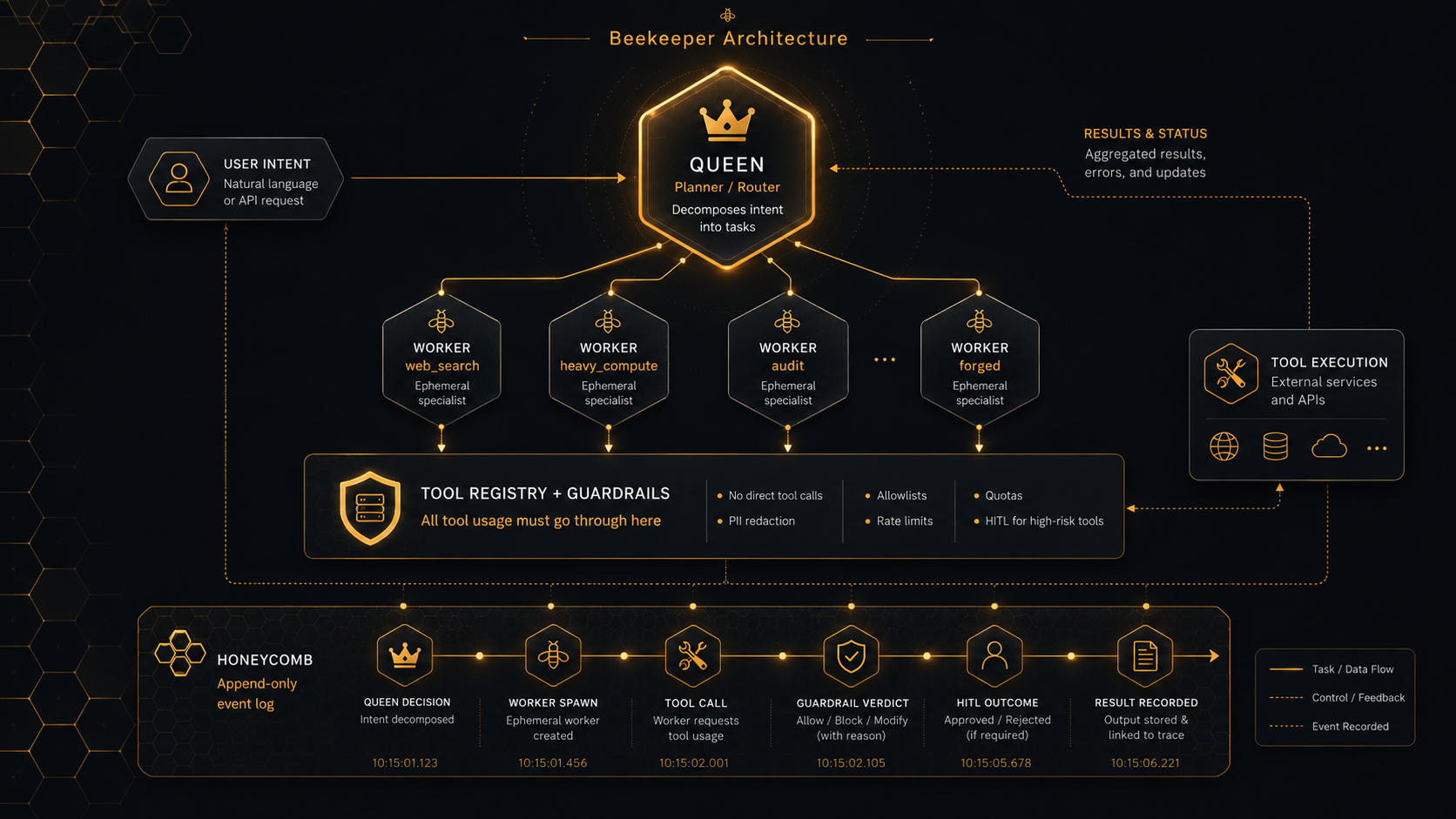
Queen. A planner / router. Decomposes an intent into tasks and decides which worker handles each one. The Queen does not execute tools.
Workers. Ephemeral specialists — web_search, heavy_compute, audit, and a forged worker for intents that don’t match an existing kind. Workers are spun up per task, not long-lived.
Tool Registry + Guardrails. Every tool a worker wants to call goes through a registry. The registry runs guardrails: PII redaction, domain allowlists, rate limits, quotas, and an HITL gate for high-risk tools. No worker ever calls a tool directly. The buffer exists by construction — there’s no codepath that bypasses it, because it’s the same codepath every time.
Honeycomb. An append-only event log. Every Queen decision, every worker spawn, every tool call, every guardrail verdict, every HITL outcome is written. If something goes wrong, you can replay the run, diff it against another run, and see the exact moment the decision diverged.
That’s the whole shape. The runtime is small on purpose.
The three things that make Beekeeper different
I’m not going to claim Beekeeper is the most performant or the most feature-rich agent framework. It isn’t. Three things are different:
1. Tool-level policy is mandatory, not opt-in
Most agent frameworks treat policy as a wrapper you add later. In Beekeeper, the registry is in the call path. There is no direct_call(). There is no unsafe_mode. If you want to bypass guardrails, you have to fork the runtime — and at that point you’ve made a decision you can be held responsible for.
This sounds like a small thing. It is the entire thing. Policy you can opt out of is policy that will be opted out of, the first time someone is in a hurry.
2. HITL is a default, not a feature
Tools registered as high-risk pause the agent and surface a review request. The reviewer sees the tool call, the args, the worker’s stated reason, and the trace context. They approve, deny, or amend. The decision is recorded.
You can configure the threshold. You can configure who reviews. What you cannot do is turn HITL off globally. Critical-blast-radius tools route through it whether you remembered to wire it up or not.
3. Every decision is replayable
I’ve been on the wrong end of “the agent did something weird and we don’t know why” debugging sessions. They are awful. The model is non-deterministic, the prompt context has rotted, and the logs you do have are partial.
Beekeeper records the full event stream. Plan, dispatch, tool input, guardrail verdict, tool output, error frames, HITL transcript. The whole timeline. You can replay a run, you can diff two runs, you can grep for “every time the audit worker fired in the last 24h.”
The opinionated bits — things I expect pushback on
A few decisions where I picked the unfashionable side:
- Workers are ephemeral, not persistent. Long-lived “agent personas” are a coordination nightmare. A new worker per task is simpler and the per-task cost is rounding error vs the LLM call.
- Dual execution mode (
legacy_worker,model_tools,hybrid). I think the eventual answer ismodel_tools, but the model-driven tool loop still has rough edges, andlegacy_workeris more debuggable for now. Both share the same registry + guardrails. - Honeycomb is JSONL by default, Postgres on the production path. The “obvious” choice was to ship Postgres-only, but JSONL on a fresh laptop is the right starting experience for OSS contributors. Configurable up.
- The worker forge is sandboxed but not yet provenance-gated. I’d rather ship the seam visible than pretend the gate is finished.
I expect to be wrong about at least one of these. That’s what Discussions is for.
Why I’m gating contributions from day one
Here is the ugly thing nobody quite wants to say in public: public OSS issue trackers in 2026 are mostly noise.
The same AI that made building Beekeeper fun also made “polished, plausible, wrong issue” trivially generable. Maintainers everywhere are drowning. The default response — try to triage everything, feel guilty, eventually burn out, archive the project — is a known failure mode and I’d rather not run the experiment again on a project I just shipped.
So Beekeeper ships with a contribution gate, ported almost verbatim from badlogic/pi-mono, which faces the same problem and solved it well. The mechanics:
- Issues from non-allowlisted contributors auto-close on creation. A bot leaves a comment explaining why and pointing at
CONTRIBUTING.md. - PRs from non-allowlisted contributors auto-close on creation, with a stricter message: open an issue first.
- Maintainer comments approve contributors.
lgtmion a closed issue means “your future issues will stay open.”lgtmmeans “your future issues and PRs will stay open.” A workflow updates the allowlist, reopens the issue, and writes back to the repo. - Issues opened Friday–Sunday UTC are auto-closed and not part of the Monday queue. Maintainers need time off the tracker.
You’ll read this and think it’s hostile. It isn’t. It’s the opposite of hostile — it’s a buffer that lets the tracker be reviewed on a maintainer’s schedule instead of the tracker’s. The bar to be approved is low: one short, concrete, well-written issue. The bar to get through the gate by spamming is high: you can’t.
If you genuinely want to contribute, I want to hear from you. The path is in CONTRIBUTING.md and the FAQ at the bottom of that file answers most of the obvious objections.
Credit where it’s due. @badlogic figured out this whole approach for
pi-monoand made the workflows public-domain-quality enough that I could port them in an afternoon. Thelgtm/lgtmidistinction in particular is his — and it’s the small detail that makes the model work.
What I want from readers
Three things, in order:
- Star the repo if governed agents, HITL on tool execution, or replayable trace logs are your problem space. It signals to me what to invest in.
- Use Discussions for questions, ideas, use cases, “have you thought about X.” Discussions are not gated.
- Open an issue if you’ve actually tried Beekeeper, hit a real bug, and have a one-screen reproducible report. Read
CONTRIBUTING.mdfirst; the gate will close it otherwise.
For security issues, do not file public issues. Use the private security advisory channel. The policy is in SECURITY.md.
What’s next
A short roadmap I’m willing to commit to:
- Worker forge sandboxing + provenance gates — the forge can already generate workers; the next step is constraining what they can do and recording who/what asked for them.
- MCP client polish — Beekeeper consumes MCP tools today; resources and prompts are next.
- Richer Honeycomb queries — replay-and-diff between two runs, time-travel through a single run, “show me every time worker X was spawned in this trace.”
- Production path docs — the Postgres + Temporal + S3 + OpenTelemetry path works; the docs don’t yet match the code’s confidence.
I’ll be writing follow-up posts as I get there.
Closing
Beekeeper is a small project with a small maintainer pool, opinionated defaults, a contribution gate that protects both me and you from low-signal noise, and a runtime that takes governance seriously because that was the actual reason I started building it.
If you’ve ever watched an agent do something destructive and thought “there should have been a moment between the decision and the action” — that moment is what Beekeeper is.
- Repo: github.com/Anmolnoor/beekeeper
- License: Apache 2.0
Thanks for reading.